


Project Title
Predictive LLM Operations & Optimization Platform
Client Snapshot
Industry: AI-Powered Customer Experience & Fintech Solutions
Company Size: 100+ employees
Region: GCC
Stage When We Entered: The client was rapidly deploying several LLM-powered applications. However, they struggled with a lack of centralized observability, making it difficult to debug prompt performance, trace complex LLM workflows across different models, and ensure consistent, reliable outputs at scale.
Challenge
Our client, a leading AI-powered firm in the GCC, faced significant hurdles in managing their rapidly expanding LLM applications. They struggled with a lack of centralized observability, making debugging complex LLM workflows incredibly difficult. This led to inconsistent model outputs, inefficient prompt engineering, and scalability bottlenecks, ultimately hindering their ability to rapidly deploy and reliably maintain their cutting-edge generative AI solutions.
The Journey
We began with a focused assessment of the client’s LLM landscape and operational challenges. This led to the seamless integration of our Managed LLM Operations & Optimization Platform, tailored to their specific workflows. We then onboarded their teams, empowering them with advanced observability and prompt engineering tools for rapid iteration and continuous evaluation, ensuring a smooth transition to optimized LLM operations.
Solution
ITechCare implemented a comprehensive Managed LLM Operations & Optimization Platform, a hosted solution built upon a leading open-source framework. This platform provides the client with a unified environment for all their generative AI initiatives, offering:
-
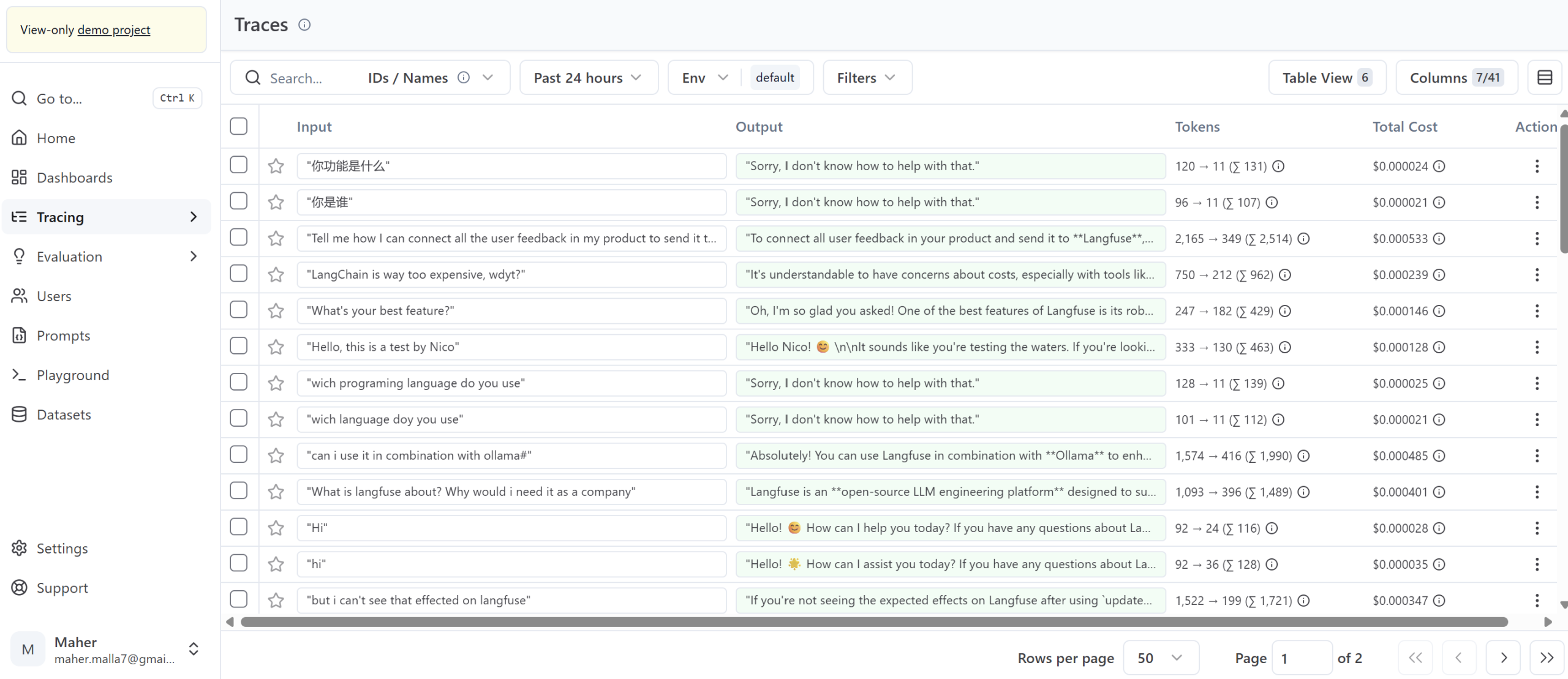
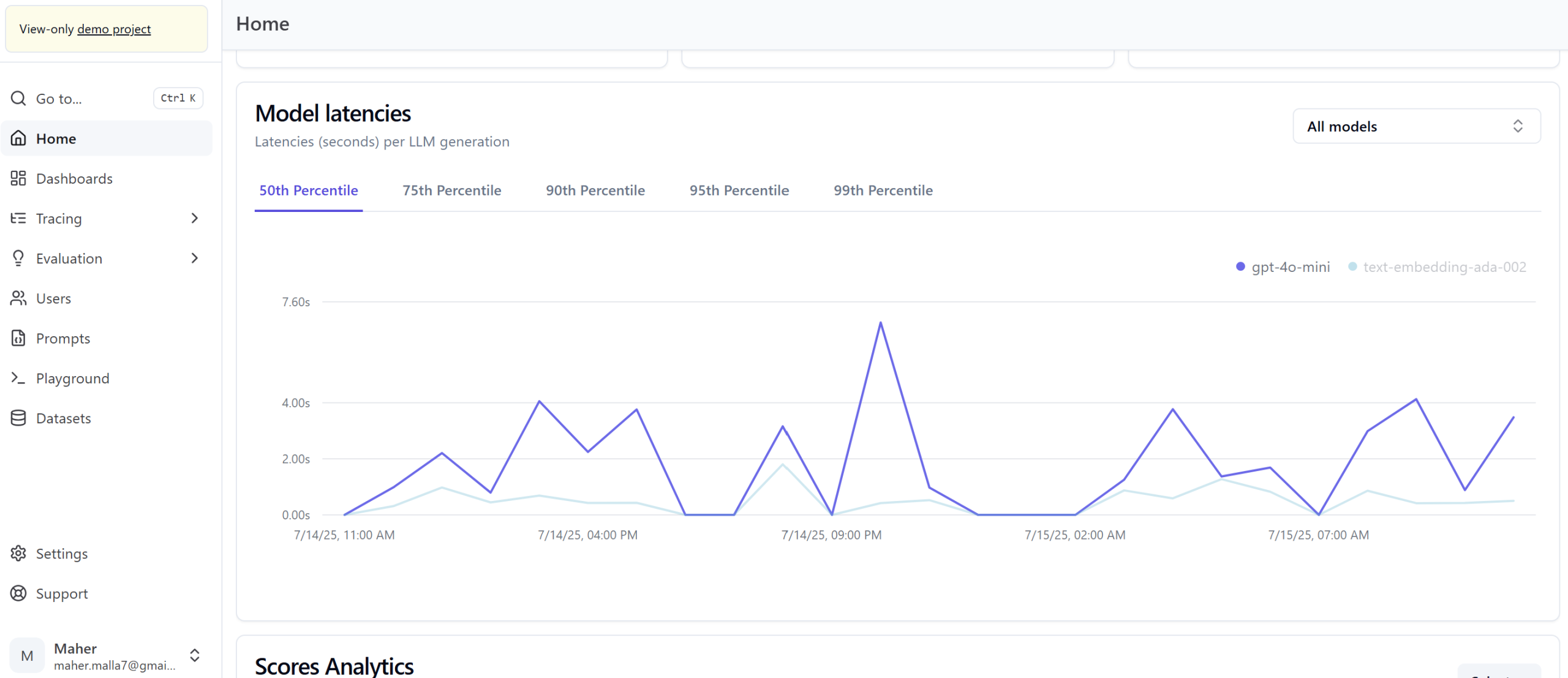
End-to-End Observability: Detailed tracing and debugging of LLM workflows, prompt performance, and API interactions, eliminating blind spots.
-
Integrated Prompt Engineering: Tools for rapid prompt iteration, experimentation, and version control.
-
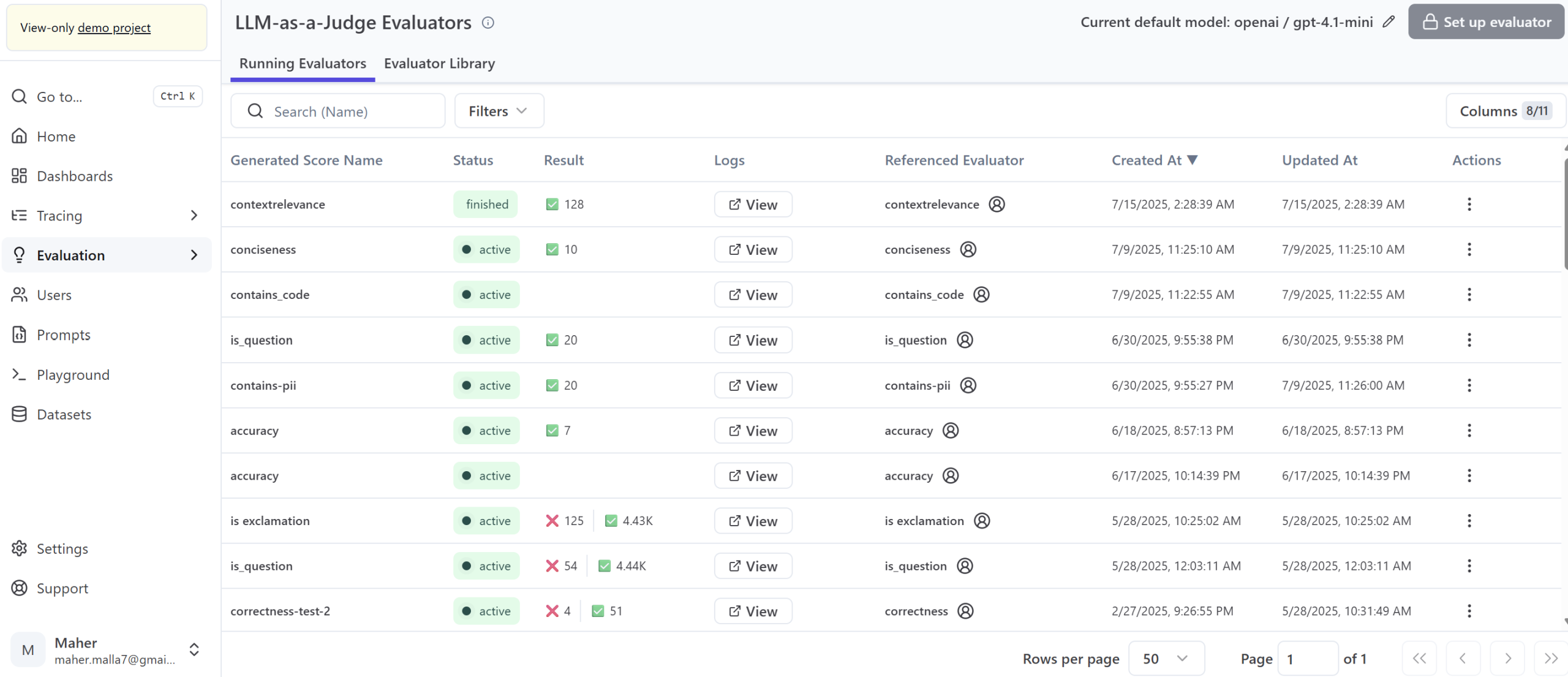
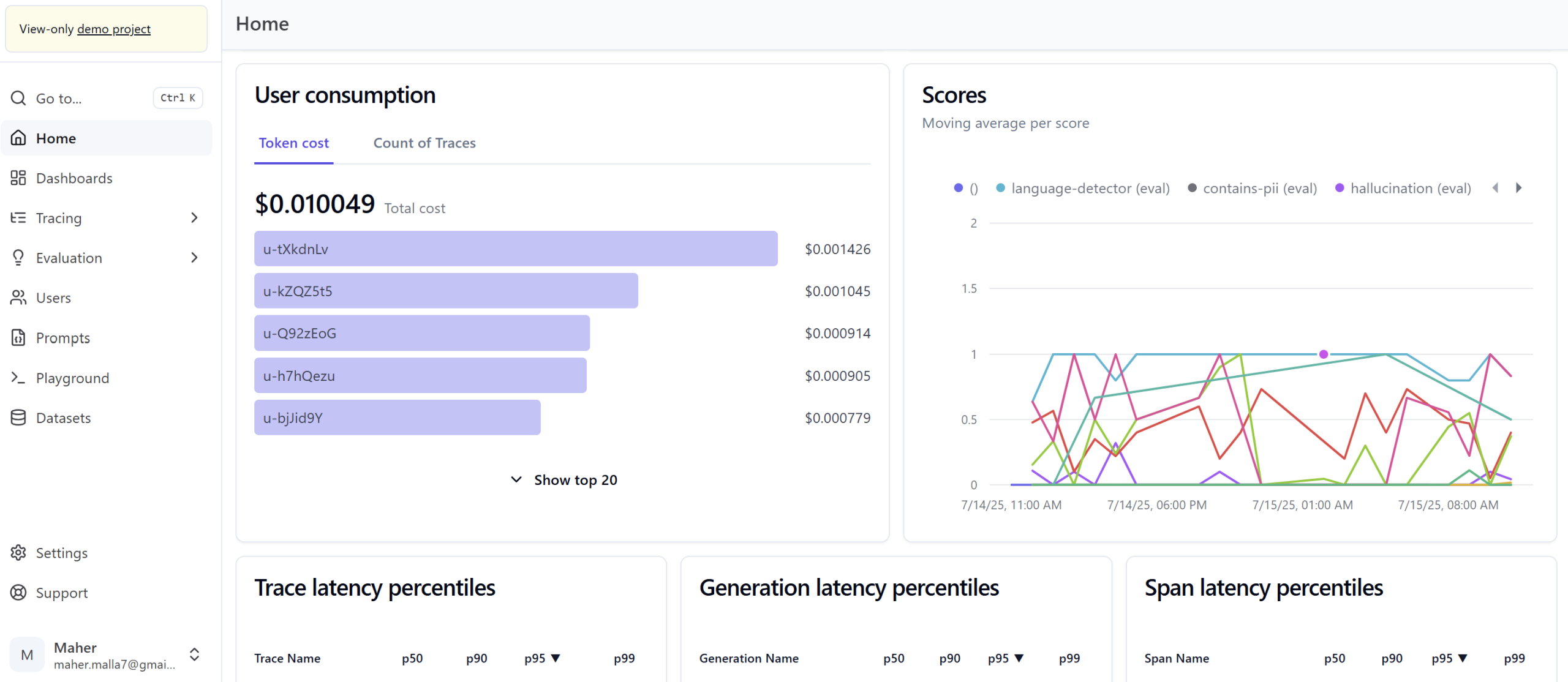
Automated Evaluation & Optimization: Continuous assessment capabilities to ensure model reliability and output quality.
This consolidated approach empowers the client to streamline LLM development, achieve consistent performance, and ensure the reliability of their AI-powered applications without the burden of managing complex infrastructure.
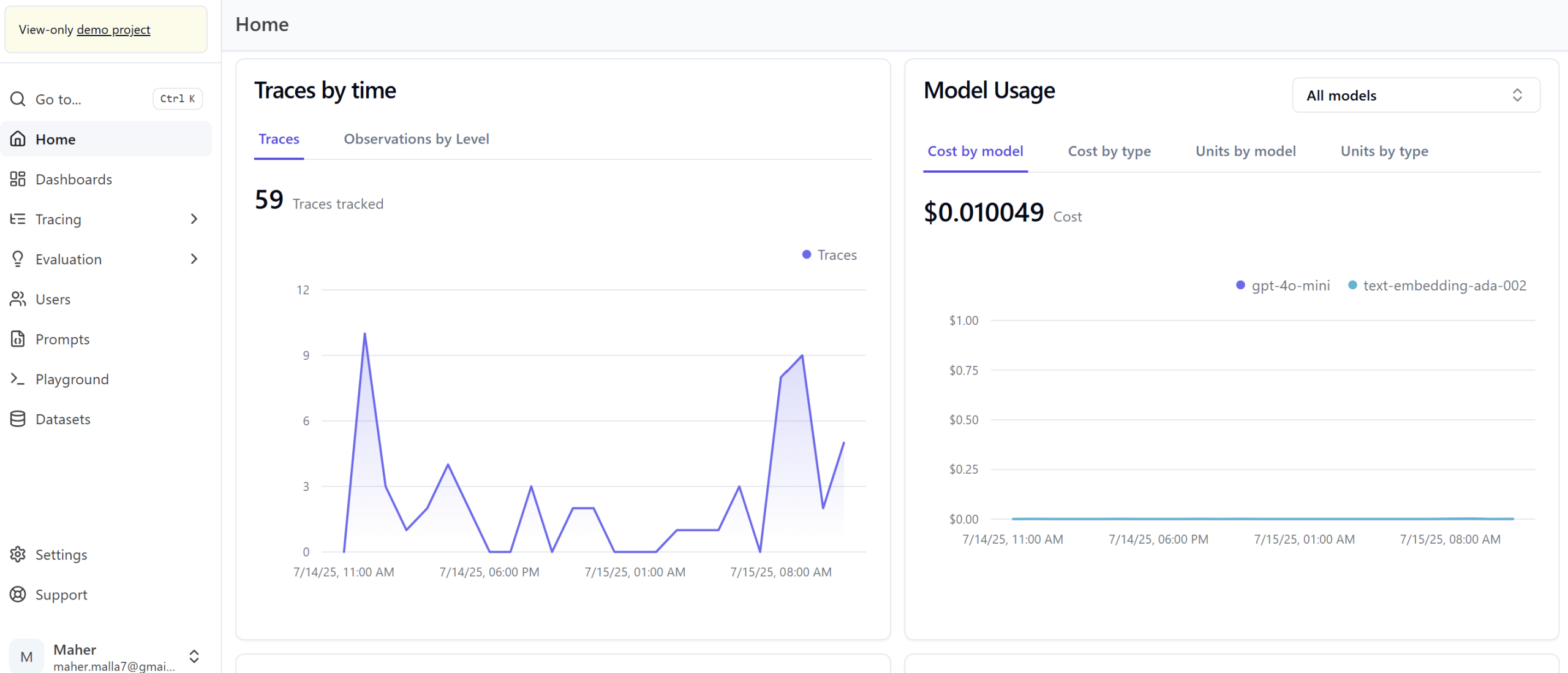
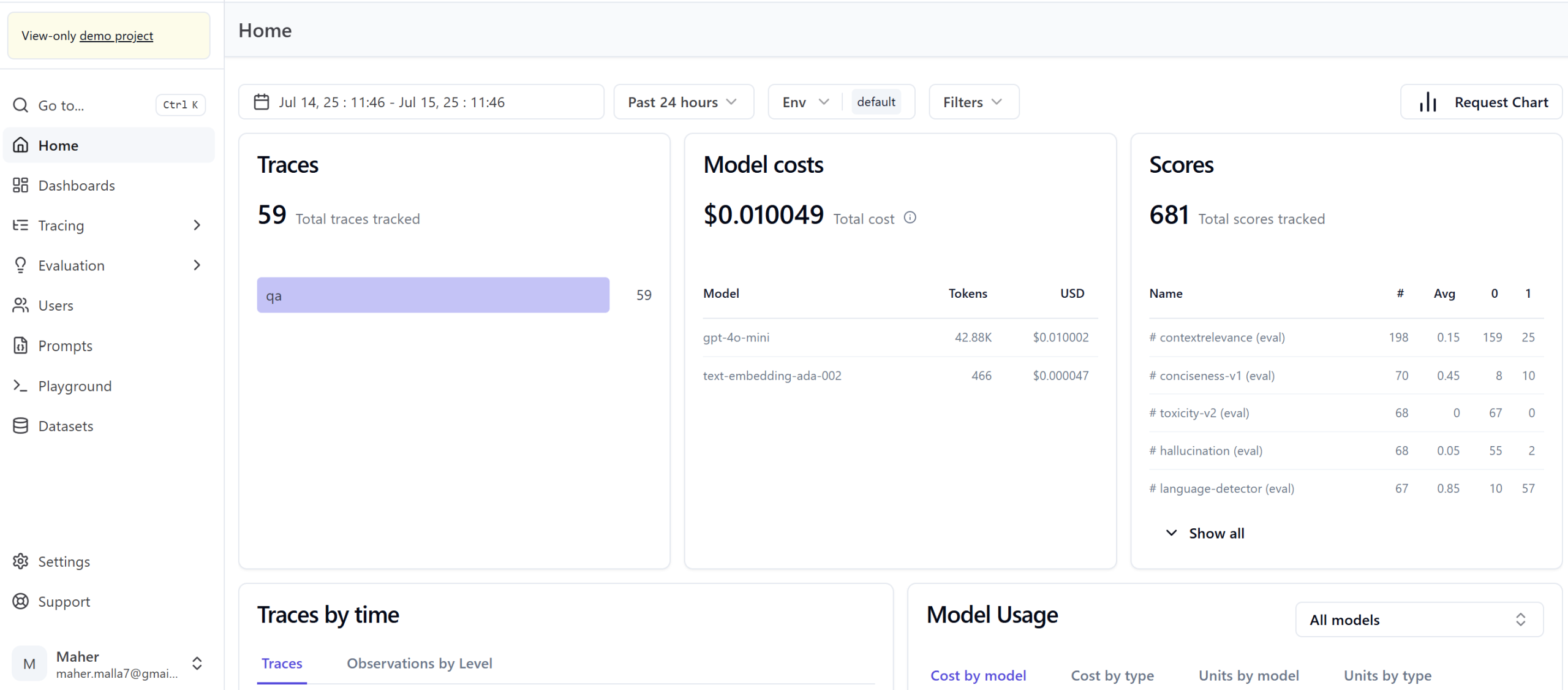
Results and ROI
-
50% Faster Iteration Cycles: Accelerated time-to-market for new LLM-powered features.
-
25% Reduction in Operational Overheads: Automated monitoring and debugging cut down manual effort and costs.
-
Improved LLM Output Quality: Consistent and reliable responses from generative AI applications, boosting user satisfaction.
-
Proactive Issue Resolution: Rapid identification and remediation of performance issues, minimizing downtime.
Why It Matters
Effectively managing and optimizing Large Language Models is crucial for any business leveraging generative AI. Our Managed LLM Operations & Optimization Platform ensures organizations can deploy robust, reliable, and high-performing AI solutions quickly, transforming complex initiatives into clear business value and securing a competitive advantage.